
变量提升
接下来咱们先看段代码,你觉得下面这段代码输出的结果是什么?
showName()
console.log(myname)
var myname = '极客时间'
function showName() {
console.log('函数showName被执行')
}使用过 JavaScript 开发的程序员应该都知道,JavaScript 是按顺序执行的。若按照这个逻辑来理解的话,那么:
- 当执行到第 1 行的时候,由于函数 showName 还没有定义,所以执行应该会报错;
- 同样执行第 2 行的时候,由于变量 myname 也未定义,所以同样也会报错。
然而实际执行结果却并非如此, 如下图:
//函数showName被执行
// undefined我们可以得出如下三个结论:
- 在执行过程中,若使用了未声明的变量,那么 JavaScript 执行会报错。
- 在一个变量定义之前使用它,不会出错,但是该变量的值会为 undefined,而不是定义时的值。
- 在一个函数定义之前使用它,不会出错,且函数能正确执行。
第一个结论很好理解,因为变量没有定义,这样在执行 JavaScript 代码时,就找不到该变量,所以 JavaScript 会抛出错误。
但是对于第二个和第三个结论,就挺让人费解的:
- 变量和函数为什么能在其定义之前使用?这似乎表明 JavaScript 代码并不是一行一行执行的。
- 同样的方式,变量和函数的处理结果为什么不一样?比如上面的执行结果,提前使用的 showName 函数能打印出来完整结果,但是提前使用的 myname 变量值却是 undefined,而不是定义时使用的“极客时间”这个值。
变量提升(Hoisting)
要解释这两个问题,你就需要先了解下什么是变量提升。
不过在介绍变量提升之前,我们先通过下面这段代码,来看看什么是 JavaScript 中的声明和赋值。
var myname //声明部分
myname = '极客时间' //赋值部分
function foo() {
console.log('foo')
}
var bar = function () {
console.log('bar')
}第一个函数 foo 是一个完整的函数声明,也就是说没有涉及到赋值操作;第二个函数是先声明变量 bar,再把 function(){console.log('bar')}赋值给 bar。
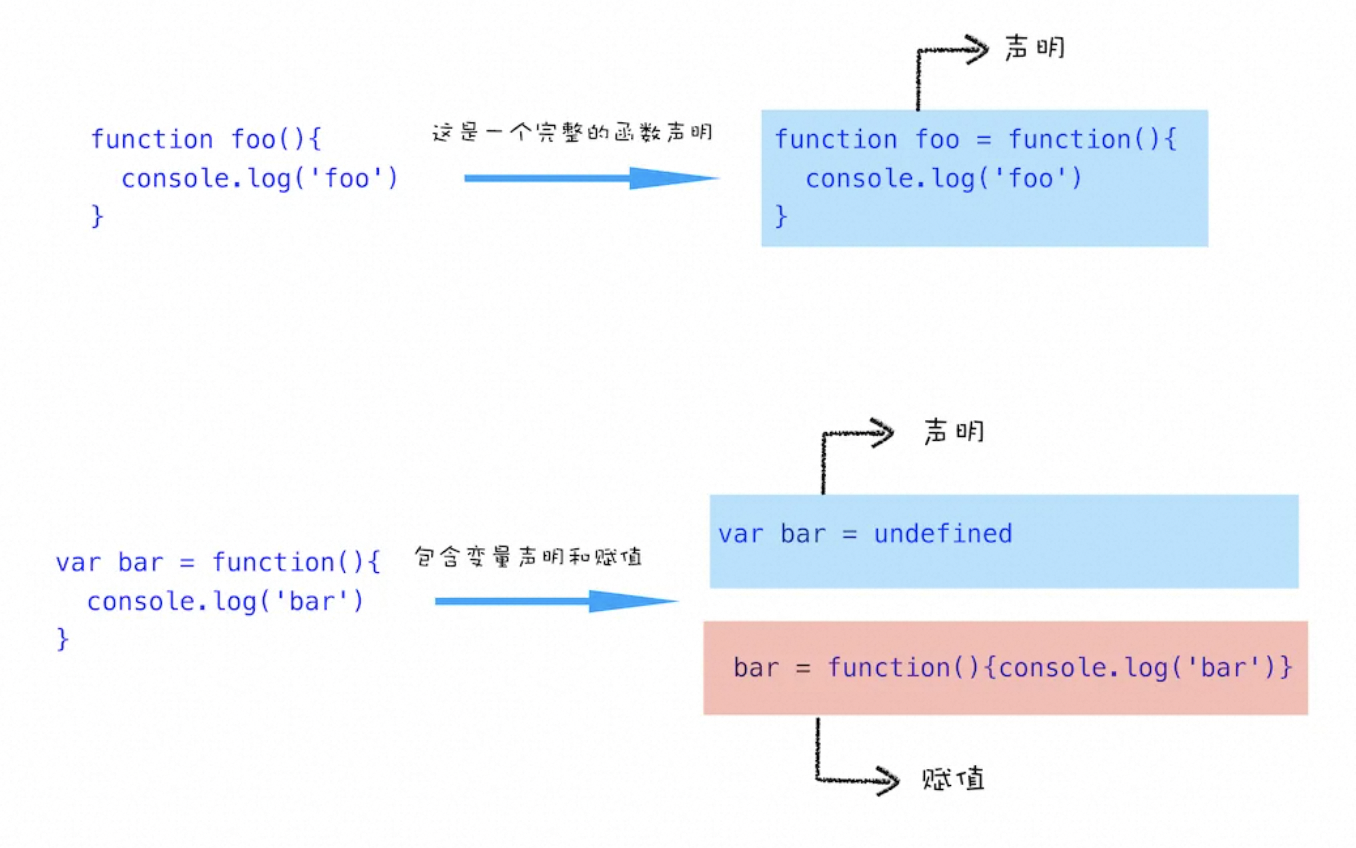
所谓的变量提升,是指在 JavaScript 代码执行过程中,JavaScript 引擎把变量的声明部分和函数的声明部分提升到代码开头的“行为”。变量被提升后,会给变量设置默认值,这个默认值就是我们熟悉的 undefined。
下面我们来模拟下实现:
/*
* 变量提升部分
*/
// 把变量 myname提升到开头,
// 同时给myname赋值为undefined
var myname = undefined
// 把函数showName提升到开头
function showName() {
console.log('showName被调用')
}
/*
* 可执行代码部分
*/
showName()
console.log(myname)
// 去掉var声明部分,保留赋值语句
myname = '极客时间'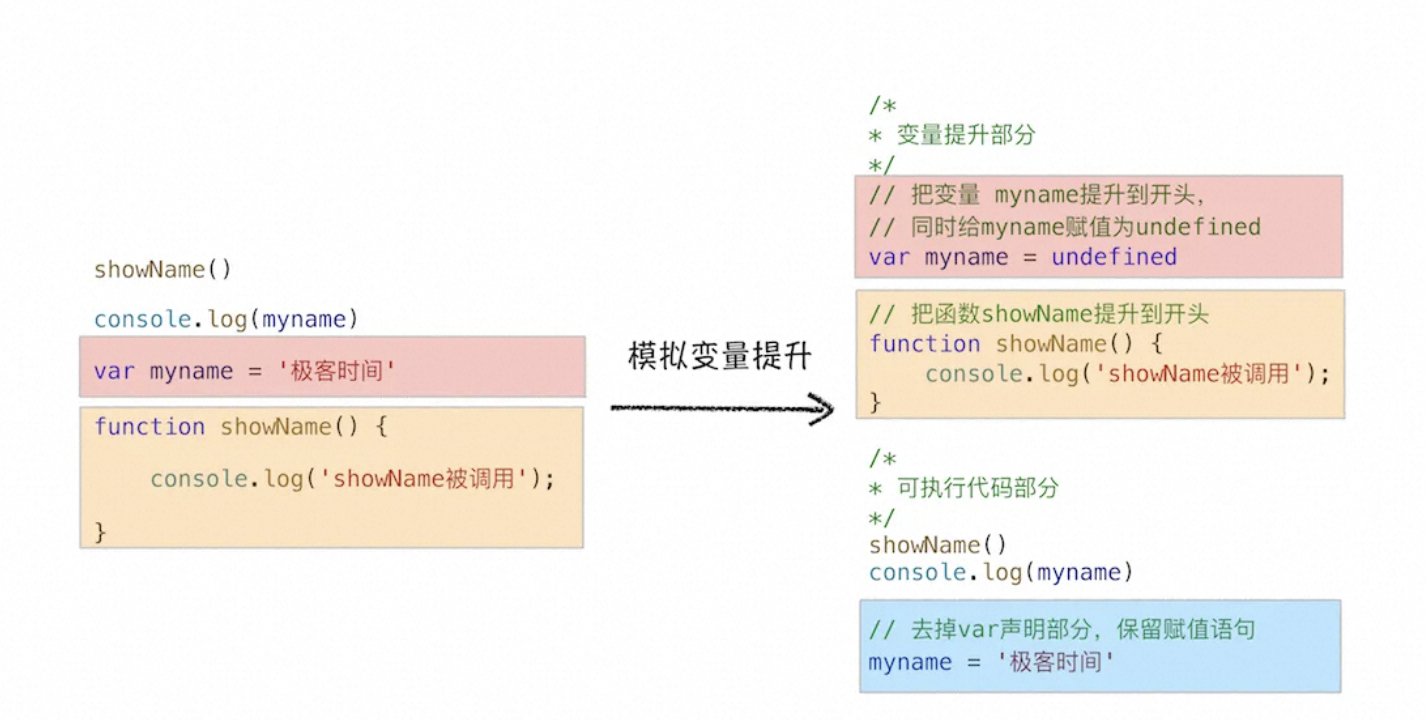 模拟变量提升示意图
模拟变量提升示意图
从图中可以看出,对原来的代码主要做了两处调整:
- 第一处是把声明的部分都提升到了代码开头,如变量 myname 和函数 showName,并给变量设置默认值 undefined;
- 第二处是移除原本声明的变量和函数,如 var myname = '极客时间'的语句,移除了 var 声明,整个移除 showName 的函数声明。
通过这两步,就可以实现变量提升的效果。你也可以执行这段模拟变量提升的代码,其输出结果和第一段代码应该是完全一样的。
通过这段模拟的变量提升代码,相信你已经明白了可以在定义之前使用变量或者函数的原因——函数和变量在执行之前都提升到了代码开头。
JavaScript 代码的执行流程
从概念的字面意义上来看,“变量提升”意味着变量和函数的声明会在物理层面移动到代码的最前面,正如我们所模拟的那样。但,这并不准确。实际上变量和函数声明在代码里的位置是不会改变的,而且是在编译阶段被 JavaScript 引擎放入内存中。对,你没听错,一段 JavaScript 代码在执行之前需要被 JavaScript 引擎编译,编译完成之后,才会进入执行阶段。大致流程你可以参考下图: 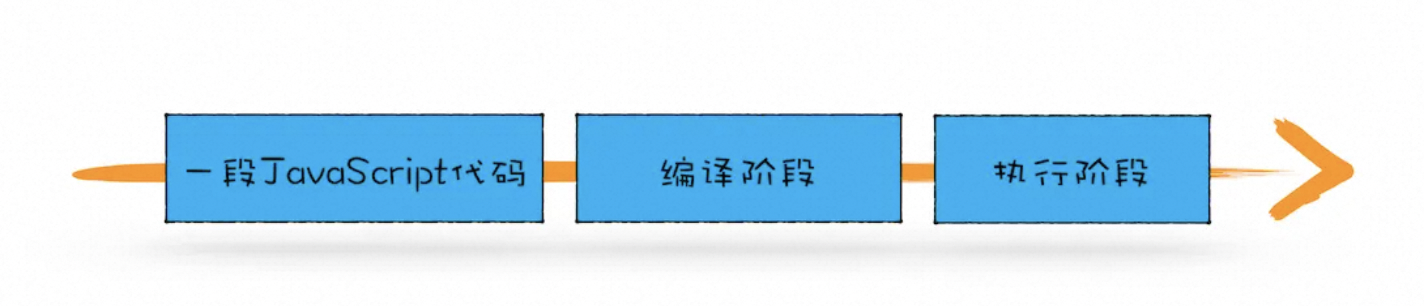
1. 编译阶段
那么编译阶段和变量提升存在什么关系呢?
为了搞清楚这个问题,我们还是回过头来看上面那段模拟变量提升的代码,为了方便介绍,可以把这段代码分成两部分。
第一部分:变量提升部分的代码
var myname = undefined
function showName() {
console.log('函数showName被执行')
}第二部分:执行部分的代码。
showName()
console.log(myname)
myname = '极客时间'下面我们就可以把 JavaScript 的执行流程细化,如下图所示: 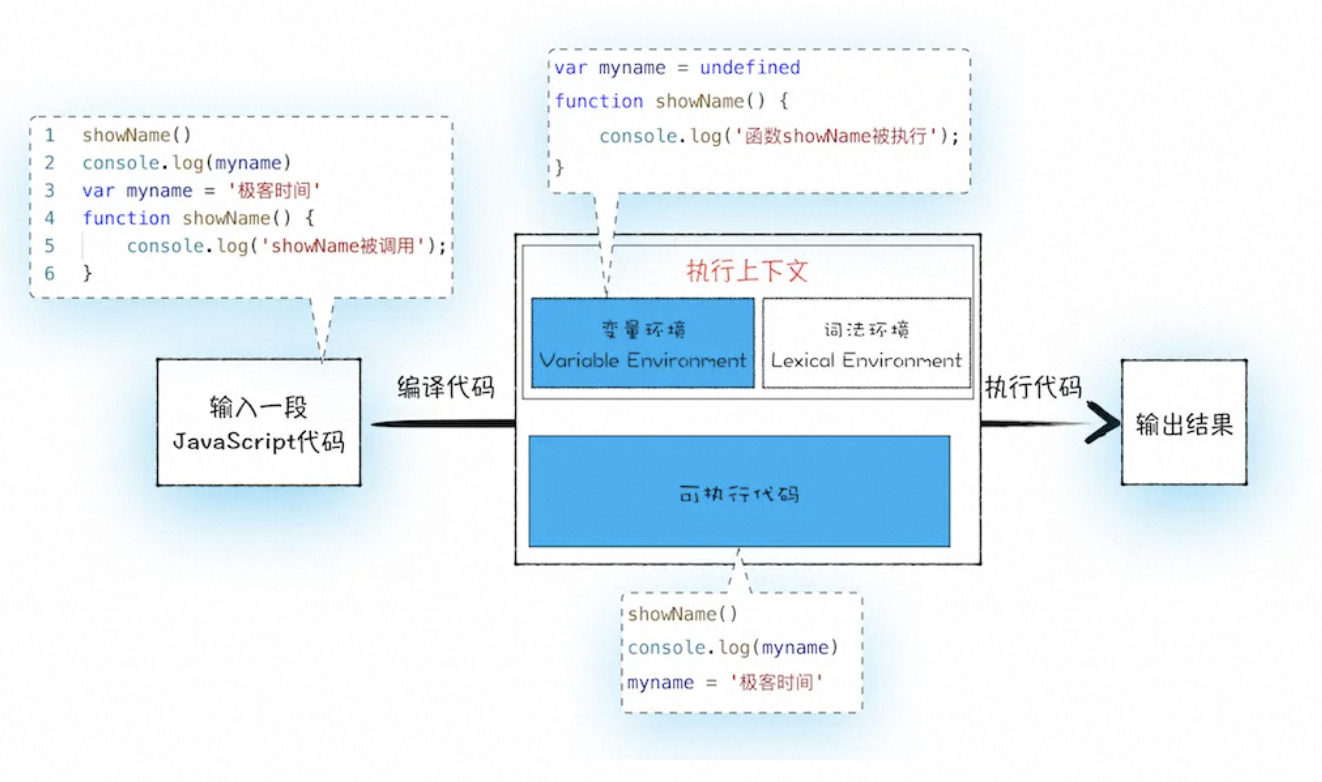
从上图可以看出,输入一段代码,经过编译后,会生成两部分内容:执行上下文(Execution context)和可执行代码。
执行上下文是 JavaScript 执行一段代码时的运行环境,比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的诸如 this、变量、对象以及函数等。
在执行上下文中存在一个变量环境的对象(Viriable Environment),该对象中保存了变量提升的内容,比如上面代码中的变量 myname和函数 showName,都保存在该对象中。
你可以简单地把变量环境对象看成是如下结构:
VariableEnvironment:
myname -> undefined,
showName ->function : {console.log(myname)}
```了解完变量环境对象的结构后,接下来,我们再结合下面这段代码来分析下是如何生成变量环境对象的。
showName()
console.log(myname)
var myname = '极客时间'
function showName() {
console.log('函数showName被执行')
}我们可以一行一行来分析上述代码:
- 第 1 行和第 2 行,由于这两行代码不是声明操作,所以 JavaScript 引擎不会做任何处理;
- 第 3 行,由于这行是经过 var 声明的,因此 JavaScript 引擎将在环境对象中创建一个名为
myname的属性,并使用undefined对其初始化; - 第 4 行,JavaScript 引擎发现了一个通过 function 定义的函数,所以它将函数定义存储到堆
(HEAP)中,并在环境对象中创建一个showName的属性,然后将该属性值指向堆中函数的位置(不了解堆也没关系,JavaScript 的执行堆和执行栈我会在后续文章中介绍)。
这样就生成了变量环境对象。接下来 JavaScript 引擎会把声明以外的代码编译为字节码,至于字节码的细节,我也会在后面文章中做详细介绍,你可以类比如下的模拟代码:
showName()
console.log(myname)
myname = '极客时间'好了,现在有了执行上下文和可执行代码了,那么接下来就到了执行阶段了。
2. 执行阶段
JavaScript 引擎开始执行“可执行代码”,按照顺序一行一行地执行。下面我们就来一行一行分析下这个执行过程
- 当执行到
showName函数时,JavaScript 引擎便开始在变量环境对象中查找该函数,由于变量环境对象中存在该函数的引用,所以 JavaScript 引擎便开始执行该函数,并输出“函数 showName 被执行”结果。 - 接下来打印
“myname”信息,JavaScript 引擎继续在变量环境对象中查找该对象,由于变量环境存在myname变量,并且其值为undefined,所以这时候就输出undefined。 - 接下来执行第 3 行,把“极客时间”赋给
myname变量,赋值后变量环境中的myname属性值改变为“极客时间”,变量环境如下所示:
VariableEnvironment:
myname -> "极客时间",
showName ->function : {console.log(myname)}好了,以上就是一段代码的编译和执行流程。实际上,编译阶段和执行阶段都是非常复杂的,包括了词法分析、语法解析、代码优化、代码生成等,这些内容我会在**《14 | 编译器和解释器:V8 是如何执行一段 JavaScript 代码的?》**那节详细介绍,在本篇文章中你只需要知道 JavaScript 代码经过编译生成了什么内容就可以了。
代码中出现相同的变量或者函数怎么办?
现在你已经知道了,在执行一段 JavaScript 代码之前,会编译代码,并将代码中的函数和变量保存到执行上下文的变量环境中,那么如果代码中出现了重名的函数或者变量,JavaScript 引擎会如何处理?
我们先看下面这样一段代码:
function showName() {
console.log('极客邦')
}
showName()
function showName() {
console.log('极客时间')
}
showName()在上面代码中,我们先定义了一个 showName 的函数,该函数打印出来“极客邦”;然后调用 showName,并定义了一个 showName 函数,这个 showName 函数打印出来的是“极客时间”;最后接着继续调用 showName。那么你能分析出来这两次调用打印出来的值是什么吗?
我们来分析下其完整执行流程:
- 首先是编译阶段。遇到了第一个 showName 函数,会将该函数体存放到变量环境中。接下来是第二个 showName 函数,继续存放至变量环境中,但是变量环境中已经存在一个 showName 函数了,此时,第二个 showName 函数会将第一个 showName 函数覆盖掉。这样变量环境中就只存在第二个 showName 函数了。
- 接下来是执行阶段。先执行第一个 showName 函数,但由于是从变量环境中查找 showName 函数,而变量环境中只保存了第二个 showName 函数,所以最终调用的是第二个函数,打印的内容是“极客时间”。第二次执行 showName 函数也是走同样的流程,所以输出的结果也是“极客时间”。 综上所述,一段代码如果定义了两个相同名字的函数,那么最终生效的是最后一个函数。
总结
- JavaScript 代码执行过程中,需要先做变量提升,而之所以需要实现变量提升,是因为 JavaScript 代码在执行之前需要先编译。
- 在编译阶段,变量和函数会被存放到变量环境中,变量的默认值会被设置为 undefined;在代码执行阶段,JavaScript 引擎会从变量环境中去查找自定义的变量和函数。
- 如果在编译阶段,存在两个相同的函数,那么最终存放在变量环境中的是最后定义的那个,这是因为后定义的会覆盖掉之前定义的。
JavaScript 的执行机制:先编译,再执行。
思考
showName()
var showName = function () {
console.log(2)
}
function showName() {
console.log(1)
}你能按照 JavaScript 的执行流程,来分析最终输出结果吗?